Architectural Strategies for Distributed System Auditing: Patterns, Compliance, and Implementation Best Practices
The transition from monolithic architectures to distributed microservices has fundamentally altered the landscape of system observability and accountability. In a monolithic environment, a single database transaction could encapsulate both a business operation and its corresponding audit entry, ensuring atomic consistency through local ACID (Atomicity, Consistency, Isolation, Durability) properties. However, in distributed systems, where business processes span multiple independent services and heterogeneous data stores, maintaining a reliable record of truth requires sophisticated design patterns and architectural rigor. Auditing in this context is no longer a peripheral concern but a core requirement for security, forensic analysis, and regulatory compliance with standards such as the General Data Protection Regulation (GDPR), Service Organization Control 2 (SOC 2), and the Health Insurance Portability and Accountability Act (HIPAA).
The Evolution of Auditability in Distributed Environments
The inherent complexity of distributed systems—characterized by network partitions, variable latency, and partial failure modes—necessitates a move away from traditional, unstructured logging toward structured, verifiable audit trails. An effective audit log entry must answer the critical questions of who initiated an action, what specific event occurred, when it happened (ideally in Coordinated Universal Time for global consistency), where the event took place (IP address or system component), and what the ultimate outcome was. Unlike application logs, which are primarily utilized for troubleshooting and may be rotated or pruned frequently, audit logs are intended for long-term retention and must be immutable and tamper-evident.
The architectural shift to microservices introduces "audit gaps" where a single user request may pass through dozens of services, each maintaining its own local state and logging its own subset of information. Without a unified strategy, correlating these disparate events into a cohesive narrative becomes an insurmountable challenge. Organizations are increasingly adopting observability design patterns—including distributed tracing, health check APIs, log aggregation, and exception tracking—to gain full-stack visibility into these complex environments. These patterns facilitate a data-driven approach to debugging and establish a concrete feedback system for improving system security and performance.
Table 1: Divergent characteristics of application and audit logging in enterprise systems.
Fundamental Design Patterns for System Integrity
To build resilient audit systems, architects must leverage specific patterns that address the challenges of service communication and data management across distributed boundaries. These patterns fall across several key areas, providing tested solutions for distributed architecture challenges such as resilience, fault handling, and event communication.
Service Communication and Discovery Infrastructure
In dynamic environments where microservices scale up or are updated to new versions, their network locations constantly change. The service registry pattern creates a central directory where services register their endpoints and health status, eliminating the need for hardcoded addresses. When services need to communicate—for instance, a payment service contacting an inventory service—they query the registry to find available, healthy instances.
Complementing this is the API gateway pattern, which creates a single entry point between clients and multiple back-end microservices. Instead of clients making separate calls to different services, the gateway receives one request, routes it appropriately, and aggregates responses. For auditing, the API gateway acts as a critical "front door," where cross-cutting concerns such as authentication, rate limiting, and initial audit logging can be centralized before requests enter the internal network.
Data Management and Transactional Consistency
The database-per-service pattern ensures that each microservice owns and manages its own database, preventing shared data dependencies and reducing coupling. While this enhances service autonomy, it complicates transactions that span multiple services. The Saga pattern addresses this by breaking distributed transactions into coordinated steps. Each service completes its local transaction and triggers the next step; if any step fails, the pattern automatically runs compensating actions to undo previous steps, maintaining eventual consistency without the overhead of distributed locks.
For auditing purposes, the Saga pattern provides a rich history of both successful actions and the remedial steps taken during failures, which is essential for understanding the complete lifecycle of complex business processes like order fulfillment or financial transfers. This is often paired with Command Query Responsibility Segregation (CQRS), which separates data modification models (commands) from retrieval models (queries). CQRS allows the system to optimize each path independently—minimizing write contention on the command side and reducing query latency on the read side, which is particularly beneficial when generating complex audit reports from high-throughput systems.
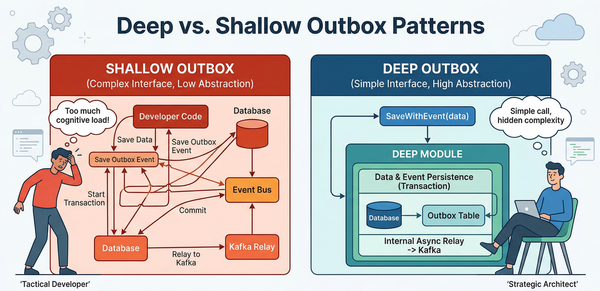
The Transactional Outbox Pattern: Solving the Dual-Write Problem
One of the most significant risks in distributed auditing is the "dual-write problem." This occurs when a single business operation requires both a database update and a message or event notification to be sent to an external system, such as a message broker or a centralized audit service. If the database update succeeds but the message dispatch fails due to a network issue or broker timeout, the system state becomes inconsistent with its audit record. Conversely, if the message is sent but the database transaction is subsequently rolled back, the audit log will contain "ghost" events that never actually occurred.
Mechanism of the Outbox and Inbox Patterns
The Transactional Outbox pattern resolves this by utilizing the local database's ACID properties to ensure atomicity. The service performs its core business logic and its audit logging as a single local transaction. It updates its primary tables and simultaneously inserts a record into a dedicated "outbox" table within the same database. Because these writes are bundled, they either both succeed or both fail.
A separate, asynchronous relay process (or message dispatcher) periodically polls the outbox table for unsent messages, publishes them to an event bus or message queue (such as Amazon SQS or Kafka), and updates their status in the outbox once delivery is confirmed. To ensure high performance and avoid lock contention, relay processes often use specific database hints.
-- Selecting unsent events with row-level locking and skipping locked rows
SELECT TOP 10 * FROM outbox
WITH (ROWLOCK, UPDLOCK, READPAST)
WHERE sent_at IS NULL
ORDER BY created_at;
The use of READPAST allows the relay process to skip rows already locked by other transactions, enabling multiple relay instances to operate in parallel without blocking each other. Furthermore, the Inbox pattern can be used on the receiving end to handle incoming messages. The receiving service first saves the incoming message into an "inbox" table and acknowledges receipt. A background job then processes the inbox rows, ensuring that even if the consumer crashes mid-processing, the message can be retried without being lost.
At-Least-Once Delivery and Idempotency
The outbox pattern guarantees "at-least-once" delivery rather than "exactly-once." If a relay process fails after sending a message but before updating the outbox status, the message will be sent again upon recovery. Consequently, downstream audit processors and consumers must be designed to be idempotent. This is typically achieved by using unique event identifiers or deterministic message generation processes, allowing systems to ignore duplicates that they have previously processed.
Table 2: Components of the Transactional Outbox pattern and their roles in maintaining data consistency.
Technical Foundations of Immutable Audit Logs
Immutability is the cornerstone of a trustworthy audit trail. If a log can be altered or deleted by an administrator or a malicious actor, its value for forensic analysis and compliance is nullified. Achieving true immutability in distributed systems relies on multi-layered cryptographic designs and append-only storage mechanisms.
Cryptographic Hashing and Hash Chains
Fundamental immutability is achieved through hash chaining, where each log record incorporates the cryptographic digest of the record that preceded it. This creates a mathematical dependency where changing any historical entry invalidates all subsequent hashes in the chain. This relationship can be expressed formally as follows:
hi=H(hi−1∥mi)
In this formula, hi represents the hash of the current record, H is a secure cryptographic hash function (such as SHA-256 or BLAKE2), hi−1 is the hash of the previous state, and mi is the current message or event data. This structure ensures "forward integrity," meaning that an auditor can verify the entire history of the log by re-computing the chain from the beginning and comparing the final result against a trusted, externally anchored hash.
Merkle Trees and Efficient Verification
While hash chains are effective for sequential integrity, they are inefficient for verifying specific records within massive datasets. Merkle trees (or binary hash trees) address this by batching log entries into a tree structure. A single Merkle root is computed over N leaf hashes recursively. This architecture enables:
- Efficient Inclusion Proofs: A specific record can be verified as part of the log in O(logN) time, requiring only a small subset of the tree hashes rather than the entire log.
- Tamper Evidence: Any modification to a leaf node propagates up to the root, making tampering immediately detectable across the entire batch.
- High Throughput: By grouping logs into Merkle trees, systems can reduce write operations and support high-throughput workloads (up to 105 logs/sec) while minimizing blockchain or ledger overhead.
Digital Signatures and Non-Repudiation
To ensure accountability and non-repudiation, every transaction or block of logs should be digitally signed using protocols like the Elliptic Curve Digital Signature Algorithm (ECDSA), Schnorr signatures, or post-quantum lattice-based primitives like CRYSTALS-Dilithium. These signatures prove that the event was recorded by a specific authorized actor and have not been altered in transit. Advanced systems are also exploring zero-knowledge proofs (ZKP) to enable "privacy-preserving" audit logs, where the validity of an event can be verified without exposing the sensitive underlying data to the auditor.
Advanced Observability Patterns: The Sidecar Model
The sidecar pattern is an architectural strategy where a "helper" container or process is deployed alongside a primary application to handle cross-cutting concerns such as logging, security, monitoring, and communication proxies. For auditing in a microservices environment, this pattern offers several critical advantages:
- Language Agnosticism: The sidecar can be written in any language and works with any application, allowing for standardized auditing across a polyglot landscape.
- Separation of Concerns: Developers can focus on core business logic while the sidecar manages the complexities of log shipping, encryption, and retry logic.
- Shared Lifecycle and Resources: In Kubernetes, the sidecar and main application share the same Pod, network namespace, and storage volumes. This allows the sidecar to read log files from a shared volume and forward them to a centralized collector without requiring network calls from the main application code.
Table 3: Common sidecar deployment strategies for distributed system auditing and observability.
Best practices for sidecar implementation include assigning health checks to the sidecar to ensure the orchestrator can detect failures, and configuring graceful shutdown handling to prevent data loss during container restarts. Resource limits should also be strictly defined, as sidecars consume CPU and memory that could otherwise be used by the primary application.
Standardization and Traceability: W3C and CloudEvents
In a distributed environment, the ability to trace a request across service boundaries is essential for auditing and forensic analysis. Two primary standards have emerged to solve the problems of correlation and interoperability: W3C Trace Context and CloudEvents.
Distributed Tracing and Context Propagation
Distributed tracing allows teams to follow the flow of a single request as it moves through multiple services. To make this work, each request receives a unique Trace ID at its point of entry. This identifier, along with a Span ID (representing the current operation) and sampling decisions, must be passed—or propagated—from one service to the next.
The W3C Trace Context specification standardizes these HTTP headers to ensure interoperability between different tracing tools and vendors:
- traceparent: Contains the version, Trace ID, Parent ID, and sampling flags.
- tracestate: Carries vendor-specific metadata, allowing different tracing systems to coexist without dropping context information.
When logging frameworks include these Trace IDs in every log entry, they create "Distributed Tracing Logs." This enables auditors to move between high-level visibility (the "map") and granular debugging (the "notes") without searching through unrelated data. Instrumentation libraries like OpenTelemetry automate much of this work by injecting headers into outgoing requests and extracting them at downstream services.
The CloudEvents Specification
While Trace Context handles the connection between events, the CloudEvents specification, hosted by the Cloud Native Computing Foundation (CNCF), standardizes the description of the events themselves. Event publishers often use proprietary formats, forcing consumers to implement custom logic for every source. CloudEvents provides a common envelope with required attributes:
- id: A unique identifier for the event occurrence.
- source: Identifies the system or component that produced the event.
- type: Indicates the kind of event (e.g.,
google.cloud.audit.log.v1.written). - specversion: The version of the CloudEvents specification used.
- time: The timestamp of when the event occurred (optional but recommended).
By adhering to this standard, organizations can build interoperable event routers, tracing systems, and audit pipelines that can process events from diverse platforms (e.g., AWS, Azure, Google Cloud) using a single, unified codebase.
Performance and Scalability Dynamics
The decision to implement auditing synchronously or asynchronously significantly impacts system latency, throughput, and data consistency. Each approach involves trade-offs that must be assessed based on the specific requirements of the application.
Synchronous vs. Asynchronous Auditing
In a synchronous communication model, a service calls another service (or the audit log system) and waits for a response before continuing execution. This is commonly implemented using REST APIs or gRPC. While this ensures immediate feedback and strong consistency, it increases latency and creates tight coupling, where a failure in the audit system can cascade and impact the primary application.
In an asynchronous model, the service publishes an event to a queue or broker and returns a successful response immediately to the caller. This decoupling improves system fault tolerance and scalability. However, under peak load, asynchronous integrations can experience significant performance degradation. For example, testing in enterprise environments has shown that while synchronous integrations maintained consistent response times during overloads, asynchronous flows experienced bottlenecks where messages waited for minutes to be dequeued for processing.
Table 4: Comparative analysis of synchronous and asynchronous audit integration patterns.
To optimize performance, a hybrid approach is often recommended. Use synchronous communication for real-time needs that require an immediate response (such as checking user permissions) and asynchronous events for the broader audit trail and downstream analysis.
Security and Privacy Engineering: PII Masking and Redaction
Audit logs often capture sensitive data, creating a tension between the need for accountability and the requirements of privacy regulations like GDPR, which mandate data minimization and purpose limitation. Architects must implement strategies for identifying, classifying, and protecting Personally Identifiable Information (PII) within their audit streams.
Redaction vs. Masking Strategies
The choice between redaction and masking depends on the required utility of the data after it has been processed.
- Data Redaction: The irreversible removal or obscuring of sensitive information. It is the safer choice when absolute data protection is non-negotiable, such as when sharing information with external parties or complying with breach notification laws.
- Data Masking: Disguising sensitive information with fictional but realistic data. Unlike redaction, masking preserves the format and structural integrity of the data, making it usable for testing, quality assurance, and AI model training without exposing real identities.
Implementing a Centralized Masking Pipeline
Best practices suggest centralizing PII scrubbing in a single telemetry collector (such as the OpenTelemetry Collector) rather than scattering masking logic throughout various services. A multi-layered pipeline allows for efficient processing:
- Attributes Processor: Operates on known keys first (e.g., hashing
user.idor deletingpassword). This is the "cheapest" operation as it avoids expensive regex. - Redaction Processor: Scans attribute values using regex patterns to catch PII patterns like SSNs or credit card numbers.
- Transform Processor: Uses the OpenTelemetry Transformation Language (OTTL) to scrub PII from log bodies and metric labels.
This ordering ensures that the volume of data evaluated with regex is minimized, protecting system performance while maintaining rigorous compliance. Furthermore, monitoring the redaction pipeline—tracking the number of blocked or modified values—can provide early warnings if a newly deployed service is leaking raw PII.
Storage and Archival Lifecycle Management
A distributed audit system must handle massive volumes of data while ensuring long-term durability, accessibility, and cost-effectiveness.
Streaming Platforms and Real-Time Compliance
Streaming platforms like Apache Kafka are frequently used for audit log ingestion because their append-only architecture provides a natural safeguard against data tampering. Kafka supports real-time processing with extremely low latency, enabling security teams to move from reactive investigation to proactive threat detection by alerting on suspicious patterns (e.g., high volumes of failed logins) as they happen.
Tiered Storage and WORM Immutability
Retaining audit logs for years to meet mandates (e.g., 7 years for SOX or 6 years for HIPAA) can be prohibitively expensive on primary storage. Modern systems employ tiered storage:
- Hot Storage: Recent, frequently accessed logs kept in high-performance databases (e.g., Cassandra or InfluxDB).
- Warm/Cold Storage: Older, less frequently accessed data automatically moved to cheaper object storage (e.g., Amazon S3 or Tencent COS).
To ensure these archived logs remain tamper-proof, they should be stored using a Write-Once, Read-Many (WORM) model. Amazon S3 Object Lock, for instance, prevents objects from being deleted or overwritten for a fixed duration. It offers two modes:
- Governance Mode: Users with specific permissions can bypass the lock; useful for internal data management and testing.
- Compliance Mode: No user—not even the root account—can delete the object or modify the lock until the retention period expires. This provides legally binding proof of compliance for heavily regulated industries.
Table 5: Regulatory retention requirements and their impact on audit log archival strategies.
Anti-patterns and Operational Blind Spots
Building a distributed audit system is fraught with risks that can undermine the goals of transparency and reliability. Identifying these anti-patterns early in the design phase is critical for long-term success.
Single Points of Failure (SPOF) and Tight Coupling
While centralizing audit storage is a best practice, creating a single ingestion endpoint that can bring down the entire production environment if it fails is a dangerous anti-pattern. Ingestion layers should be stateless and horizontally scalable, utilizing backpressure mechanisms to buffer or shed load during traffic spikes rather than blocking the producers. Similarly, over-tight coupling—where services are excessively "chatty" and make frequent network calls for small bits of information—introduces significant latency and complexity.
Distributed Monoliths and Eventual Consistency Misunderstanding
A "distributed monolith" occurs when a system is physically distributed but logically coupled, requiring all services to be deployed and scaled together. This often stems from an overuse of synchronous communication and a failure to embrace the asynchronous, event-driven patterns necessary for true microservices autonomy.
Furthermore, developers may assume strong consistency where only eventual consistency is in place. In an audit context, this can lead to situations where an auditor sees an action (e.g., a funds transfer) before the corresponding correction or compensating transaction has been processed, leading to incorrect conclusions. Understanding these trade-offs and implementing strategies like versioning and conflict resolution is essential.
Data Lineage and Governance Gaps
Auditors need proof that data is trustworthy. A common pitfall is the lack of "data lineage"—a clear map of where data originated, how it was transformed, and its final destination. Strong data governance, including the use of a Schema Registry, ensures that audit events conform to a strict, predefined structure (e.g., Avro or Protobuf). This prevents data quality issues and provides the transparency necessary for a successful audit.
Synthesis and Strategic Recommendations
The implementation of a high-integrity audit system in a distributed environment requires a holistic approach that integrates cryptographic security, cloud-native design patterns, and rigorous operational practices. By moving beyond basic logging to a structured, verifiable audit trail, organizations can achieve true accountability and resilience.
To ensure success, architects and security leaders should prioritize the following recommendations:
- Adopt the Transactional Outbox Pattern to resolve the dual-write problem, ensuring that business state changes and audit events are committed atomically within the local database.
- Utilize Sidecar Containers for log collection and shipping to decouple auditing logic from core business applications and ensure standardized observability across polyglot services.
- Standardize on W3C Trace Context and CloudEvents to maintain transaction context across service boundaries and facilitate interoperability between diverse event publishers and consumers.
- Implement Cryptographic Immutability through hash chaining and Merkle trees, ensuring that audit logs are tamper-evident and can be efficiently verified by external parties.
- Centralize Privacy Guardrails in a dedicated telemetry pipeline to automate the masking or redaction of sensitive data, meeting GDPR and HIPAA requirements without manual overhead.
- Establish Tiered Storage and WORM Archival using tools like S3 Object Lock in Compliance Mode to manage the cost of multi-year retention while protecting logs from unauthorized deletion.
- Educate Teams on Distributed Realities, including the trade-offs of eventual consistency and the necessity of idempotency in event-driven audit consumers.
By treating auditability as a first-class architectural concern, organizations transform their logs from a compliance burden into a strategic asset that builds trust with customers, stakeholders, and regulators.