How Databases Utilize B-Trees for Storage

How Databases Store Data: An Introduction to B-Trees
As software architects, we often design systems that rely heavily on robust data storage. Understanding how databases fundamentally organize and retrieve information is crucial for building performant and scalable applications. At the heart of many relational databases lies a fascinating data structure: the B-Tree.
The Challenge of Efficient Data Retrieval
Imagine a vast library without any cataloging system. Finding a specific book would involve scanning every single shelf. Databases face a similar challenge: efficiently storing and retrieving massive amounts of data from disk. Disk I/O operations are significantly slower than memory access, so minimizing them is paramount. This is where the B-Tree shines.
What is a B-Tree?
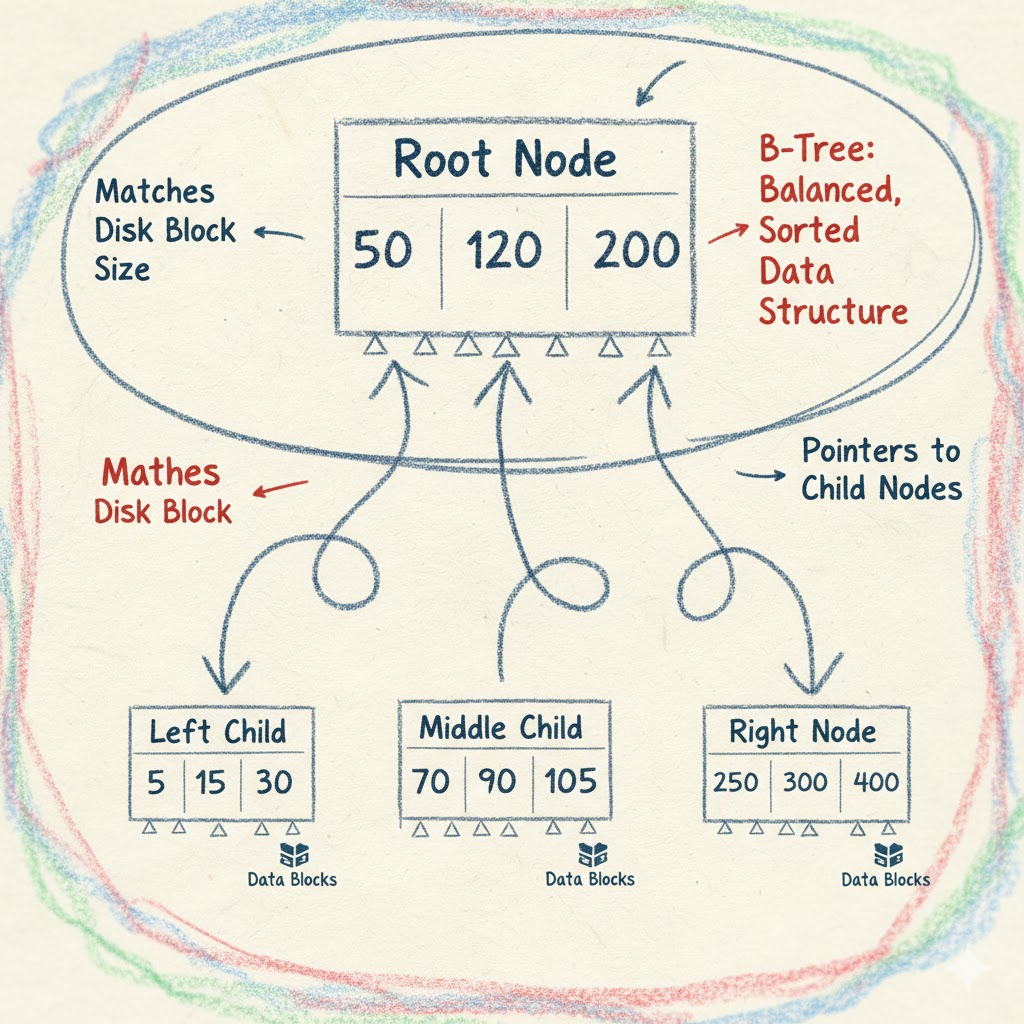
A B-Tree, or Balanced Tree, is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. Unlike binary trees, B-Trees are "fat" and "short," meaning they can have many children per node. This characteristic is vital because it reduces the height of the tree, thereby minimizing the number of disk reads required to find a piece of data.
At a high level, a B-Tree consists of nodes, which are typically sized to match disk block sizes. Each node contains a sorted list of keys and pointers to child nodes.
How Databases Utilize B-Trees for Storage
When you create an index on a column in your database, a B-Tree is often constructed behind the scenes. The keys in the B-Tree are the values from your indexed column, and the leaf nodes of the B-Tree contain pointers to the actual data rows on disk (or in some cases, the data rows themselves).
Consider an example where we're looking for a user with user_id = 150. The database traverses the B-Tree:
- It starts at the root node.
- Compares
150with the keys in the root node to determine which child pointer to follow. - This process continues until it reaches a leaf node.
- The leaf node then points to the exact disk location of the row containing
user_id = 150.
This structured approach significantly speeds up data retrieval compared to a full table scan, especially for large datasets.

Advantages and Architectural Insights
The primary advantage of B-Trees is their efficiency for disk-based storage. By maintaining balance and ensuring nodes are filled to a certain degree, they minimize tree height and thus disk I/O. This makes them ideal for:
- Database Indexes: As discussed, for fast lookups, range queries, and sorting.
- Filesystems: Many modern file systems use B-Tree variants (like B+Trees) to manage directories and file allocations efficiently.
From an architectural perspective, understanding B-Trees allows us to:
- Optimize Indexing: Choose appropriate columns for indexing, recognizing the trade-offs in storage space and write performance versus read performance.
- Diagnose Performance Issues: A slow query might indicate a missing or inefficient index, prompting an investigation into the underlying B-Tree structure.
- Design Scalable Systems: Knowing that database operations leverage B-Trees helps in anticipating performance characteristics under heavy load and designing sharding or partitioning strategies effectively.
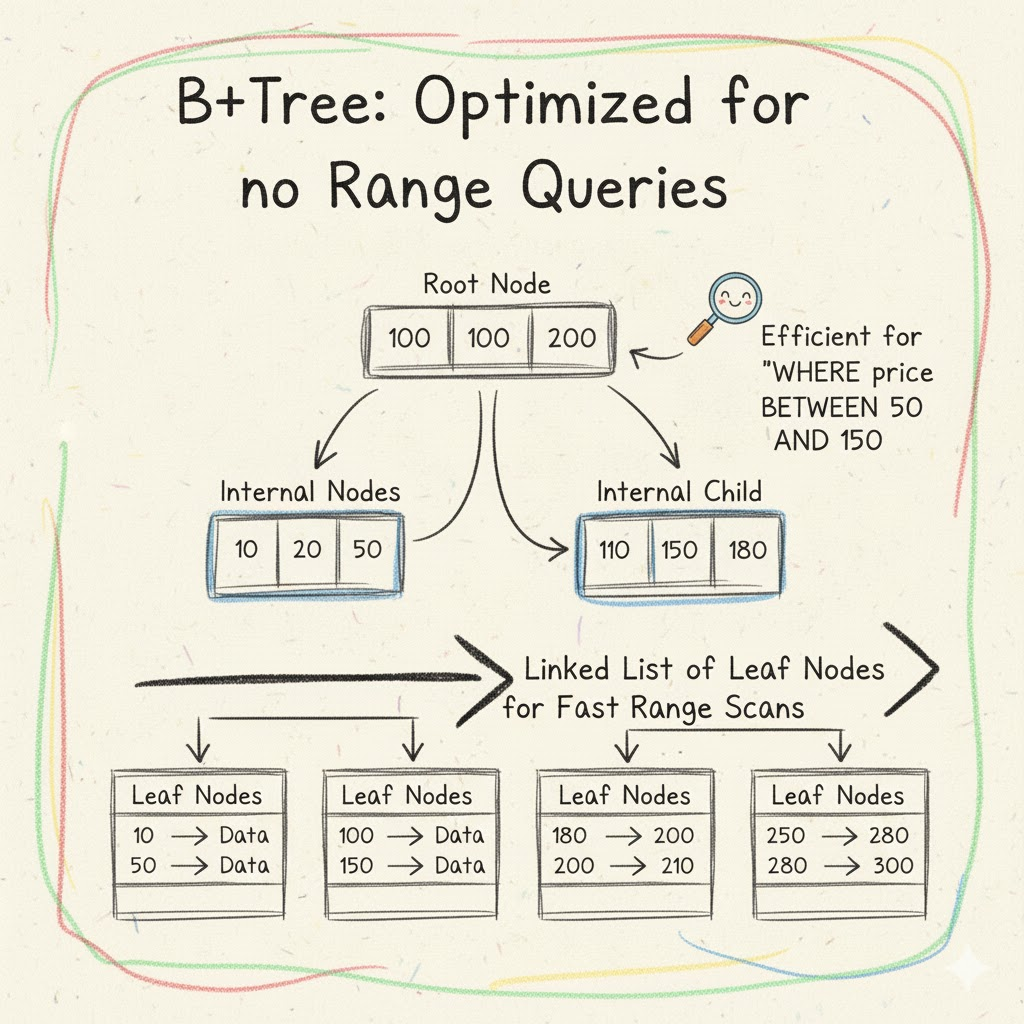
Beyond the Basics: B+Trees
While B-Trees are fundamental, many relational databases actually use a variation called a B+Tree. The key difference is that in a B+Tree, all data pointers are stored only in the leaf nodes, and these leaf nodes are linked together sequentially. This structure is particularly efficient for range queries, as once the starting point is found, the database can simply traverse the linked leaf nodes without going back up the tree.
Conclusion
The humble B-Tree, and its sibling the B+Tree, are foundational concepts in computer science and critical components in how modern databases store and retrieve data efficiently. For anyone designing or working with data-intensive applications, a solid understanding of these structures provides invaluable insight into database performance and helps in making informed architectural decisions. By minimizing disk I/O and maintaining ordered, balanced data, B-Trees continue to be a cornerstone of high-performance data storage.