Service Mesh Benefits: Why Modern Applications Need This Critical Infrastructure Layer
In the evolution of cloud-native architectures, service mesh has emerged as a fundamental infrastructure layer that addresses the complexity of microservices communication. As organizations scale their distributed systems, understanding service mesh benefits becomes essential for building resilient, observable, and secure applications.
What Is a Service Mesh?
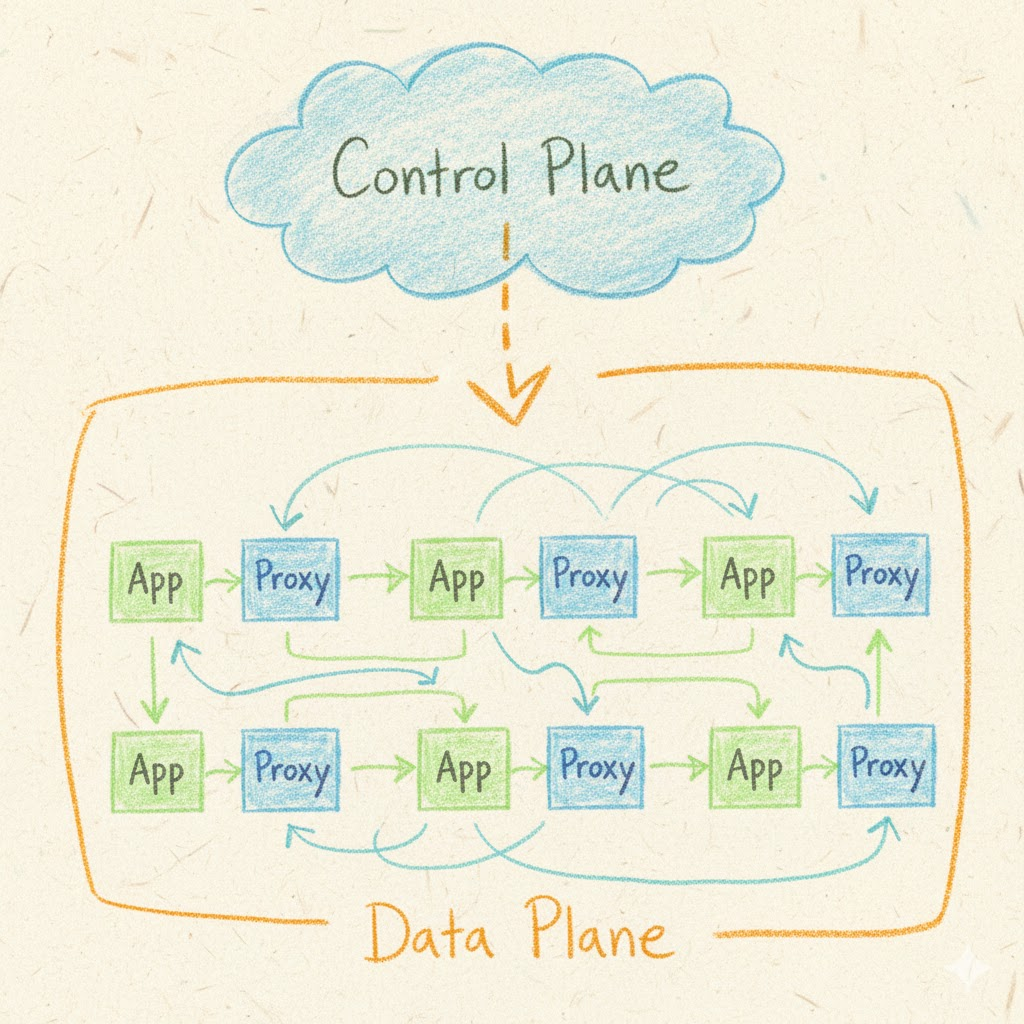
A service mesh is a dedicated infrastructure layer that manages service-to-service communication in a microservices architecture. Rather than embedding communication logic within each service, a service mesh uses a network of lightweight proxies deployed alongside application containers. This sidecar pattern decouples communication concerns from business logic, creating a consistent way to handle traffic management, security, and observability across all services.
The most widely adopted service mesh implementations—Istio, Linkerd, and Consul Connect—share a common architecture: a data plane of proxies that handle actual traffic, and a control plane that configures and manages these proxies. This separation of concerns enables centralized policy enforcement without requiring application code changes.
Core Service Mesh Benefits
Enhanced Traffic Management and Reliability
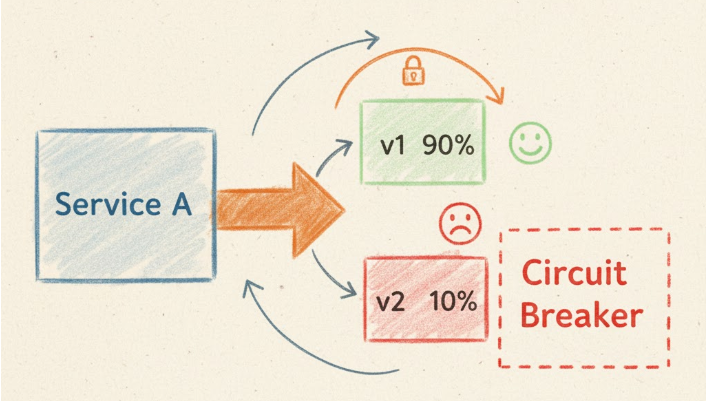
Service mesh provides sophisticated traffic control that goes far beyond traditional load balancing. Traffic splitting enables gradual rollouts through canary deployments and A/B testing, allowing teams to validate new versions with a subset of users before full deployment. Circuit breaking automatically prevents cascade failures by detecting unhealthy services and redirecting traffic, while retry logic and timeout configurations ensure graceful degradation during transient failures.
These capabilities transform deployment strategies. Instead of risky all-or-nothing releases, teams can implement progressive delivery with automated rollback triggers based on error rates or latency thresholds. The service mesh handles the complexity of routing rules, health checks, and failure detection without any changes to application code.
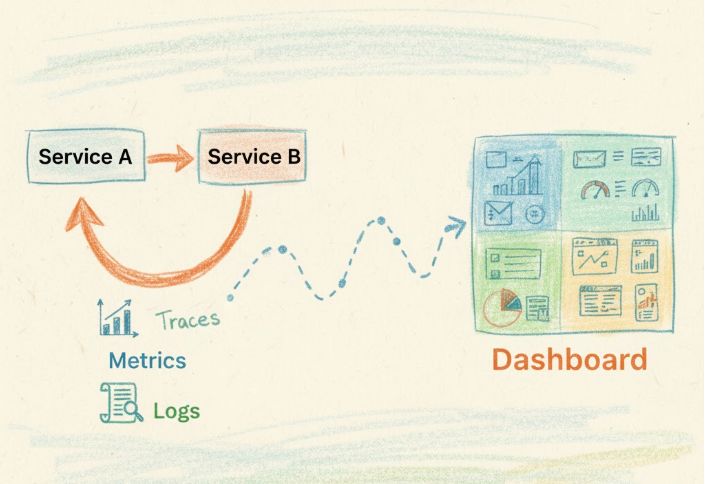
Deep Observability and Distributed Tracing
One of the most significant service mesh benefits is comprehensive observability without instrumentation overhead. The sidecar proxies automatically collect metrics for every request: latency distributions, error rates, throughput, and connection statistics. This golden signals data flows to monitoring systems like Prometheus, providing instant visibility into service health.
Distributed tracing captures request flows across multiple services, revealing bottlenecks and dependencies that are invisible in traditional monitoring. When a user reports slow response times, traces show exactly which services and external APIs contributed to latency. This level of insight accelerates troubleshooting from hours to minutes, especially in complex systems with dozens or hundreds of services.
Access logs generated by the mesh provide a complete audit trail of service communication, essential for compliance requirements and security investigations. Unlike application-level logging, these logs are consistent, structured, and impossible to bypass—every request passes through the proxy layer.
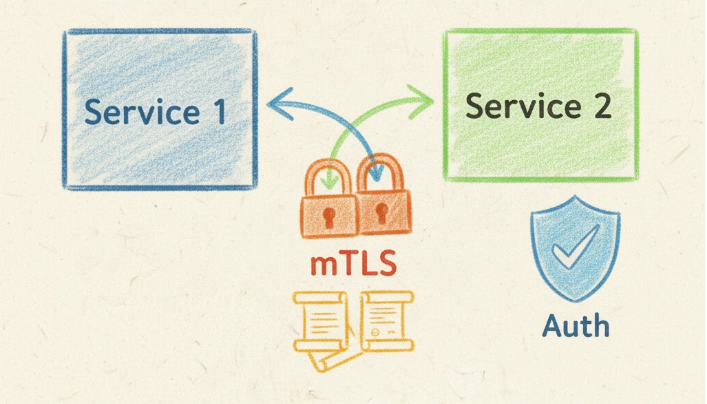
Zero-Trust Security by Default
Security represents perhaps the most compelling reason why service mesh adoption continues to accelerate. The mesh enforces mutual TLS (mTLS) between all services automatically, encrypting traffic and authenticating both parties in each connection. Certificate management, including rotation and revocation, happens transparently without application involvement.
Fine-grained authorization policies define which services can communicate based on service identity rather than network location. This zero-trust model assumes breach and limits lateral movement—even if an attacker compromises one service, the mesh prevents unauthorized communication with other services. Traditional network perimeters cannot provide this level of granular control.
Rate limiting and quota enforcement at the mesh layer protect services from both external attacks and internal misbehavior. A misconfigured service making excessive requests gets throttled automatically, preventing resource exhaustion and cascade failures.
Real-World Use Cases and Value Delivery
Multi-Cluster and Multi-Cloud Deployments
Organizations running workloads across multiple Kubernetes clusters or cloud providers face significant connectivity and security challenges. Service mesh benefits extend across cluster boundaries, providing unified traffic management and security policies regardless of where services run. A service in AWS can securely communicate with services in GCP using the same mTLS and authorization mechanisms that govern intra-cluster traffic.
This capability enables sophisticated disaster recovery strategies and regulatory compliance. Workloads can span regions for high availability, or data residency requirements can be enforced through routing policies, all managed centrally through the mesh control plane.
Migration and Hybrid Architectures
Many organizations face the challenge of gradually migrating from monolithic applications or VM-based deployments to containerized microservices. Service mesh supports this transition by providing a consistent communication layer across heterogeneous environments. Legacy services running on VMs can integrate with the mesh using gateway patterns, allowing incremental migration without disrupting existing functionality.
The mesh enables strangler fig patterns where new microservices gradually replace monolith functionality. Traffic can be split between old and new implementations based on configurable rules, with rollback capability if issues arise. This de-risks modernization initiatives that might otherwise require risky big-bang migrations.
Platform Engineering and Developer Productivity
Platform teams use service mesh to provide self-service capabilities while maintaining governance. Developers get automatic encryption, observability, and reliability features without expertise in these domains. The mesh enforces organizational standards—security policies, compliance requirements, SLO targets—as infrastructure rather than relying on individual team implementations.
This separation of concerns accelerates development velocity. Application teams focus on business logic while platform teams optimize communication patterns, security postures, and operational excellence. The result is both faster feature delivery and higher quality, as cross-cutting concerns receive dedicated, expert attention.
Challenges and Considerations
Operational Complexity
While service mesh abstracts complexity from application developers, it introduces operational overhead for platform teams. The mesh itself must be monitored, upgraded, and tuned. Control plane failures can impact all services, making high availability critical. Teams need expertise in mesh-specific concepts like virtual services, destination rules, and traffic policies.
Resource consumption deserves careful consideration. Each sidecar proxy adds CPU and memory overhead—typically 50-100MB per pod and modest CPU usage. In environments with thousands of pods, these costs accumulate. However, the operational benefits usually outweigh resource costs, especially as proxy efficiency continues improving.
Debugging Complexity
The additional layer between services can complicate troubleshooting. When issues arise, teams must determine whether the problem lies in application code, mesh configuration, or infrastructure. Proxy logs and mesh-generated metrics help, but engineers need training to interpret this data effectively. The learning curve is real, though comprehensive observability often makes debugging easier once teams adapt.
Integration and Compatibility
Not all applications fit naturally into service mesh patterns. Services with specialized networking requirements or extremely high-performance demands may struggle with the proxy overhead. Stateful services require careful configuration to ensure session affinity and connection draining work correctly. Teams should evaluate whether their specific use cases align with mesh capabilities before committing to adoption.
Architectural Insights for Successful Implementation
Start with Clear Objectives
Successful service mesh adoption begins with specific goals rather than adopting technology for its own sake. Organizations should identify concrete problems—security compliance gaps, observability blind spots, or deployment risk—and measure whether the mesh addresses these issues. Starting with a small subset of services allows teams to learn and validate benefits before organization-wide rollout.
Invest in Platform Engineering
Service mesh works best as a platform capability managed by dedicated teams. These teams need deep expertise in networking, security, and Kubernetes internals. They should provide well-documented patterns, troubleshooting runbooks, and support channels for application teams. This investment in platform engineering multiplies benefits across all teams using the mesh.
Embrace Progressive Rollout
Enabling all mesh features simultaneously overwhelms teams with complexity and increases failure risk. A phased approach works better: start with observability to build confidence, add mTLS for security improvements, then gradually enable advanced traffic management. This progression allows learning at each stage and demonstrates incremental value.
Design for Failure
The service mesh itself can fail, and configurations can be incorrect. Applications should handle mesh unavailability gracefully rather than assuming perfect reliability. Circuit breakers and timeouts configured in the mesh provide defense in depth, but application-level resilience remains important. The mesh enhances reliability but doesn't replace sound application design.
The Future of Service Mesh
Service mesh technology continues evolving rapidly. Ambient mesh architectures remove the sidecar requirement, reducing resource overhead while maintaining benefits. WebAssembly extensions enable custom functionality without forking proxy code. Multi-cluster and multi-cloud capabilities mature, making truly distributed systems more manageable.
Integration with emerging technologies shapes the roadmap. Service mesh combines with GitOps for declarative infrastructure management. eBPF-based implementations promise even lower overhead. AI-driven traffic optimization and anomaly detection will leverage the rich telemetry that meshes provide.
Why Service Mesh Matters
The question "why service mesh" ultimately comes down to managing complexity at scale. As applications grow beyond a handful of microservices, the operational burden of communication management becomes unsustainable without abstraction. Service mesh benefits include enhanced security, deep observability, and sophisticated traffic control—capabilities that are difficult or impossible to implement consistently across distributed systems otherwise.
Organizations that embrace service mesh gain competitive advantages: faster deployment cycles with lower risk, stronger security postures meeting compliance requirements, and operational insights enabling data-driven optimization. The investment in learning and implementation pays dividends as systems scale and complexity grows.
For teams building modern, cloud-native applications, understanding service mesh benefits and evaluating adoption should be a strategic priority. The technology has matured beyond early adoption into production-proven infrastructure that powers some of the world's largest and most demanding systems. The question isn't whether service mesh provides value, but whether the timing and organizational context make adoption the right next step.
Service mesh represents a fundamental shift in how distributed systems handle communication, security, and observability. By moving these concerns into dedicated infrastructure, organizations can build more reliable, secure, and manageable applications while accelerating development velocity.